
How to prevent server outages with unified observability | OneView Solution
Often underestimated, but so important for our daily work. Servers sit quietly at the heart of almost everything companies do. They are the foundation on which modern businesses are built. Without them, we would not be able to store data, run applications, or ensure round-the-clock system availability.
Instead of information being scattered across individual laptops or systems, servers allow organizations to centralize their data, and are the backbone of critical services like websites, email, and internal tools.
What is server infrastructure?
Server infrastructure refers to the complete setup that underpins this foundation. This includes physical or cloud-based servers, storage, networks, and the software that keeps everything connected and operational.
As businesses grow, this infrastructure becomes more complex and more critical. Server infrastructure stops being just “the place where things run” and becomes the engine behind almost everything the company does. In the early days, it might have been a couple of servers, a few apps, and a small team that handled everything.
But growth changes the rules. More employees need access, more customers use your services, more tools get added, and suddenly you are dealing with bigger data volumes, more systems talking to each other, and more demand for reliability. Thus, when they work well, no one notices. When they don’t, the business feels it immediately.
How to deal with a complex server infrastructure?
The first reason infrastructure becomes more complex is that many companies don’t grow their systems following good practices and with a clear strategy in mind. They grow them in a hurry. Different teams choose different tools, environments, and ways of deploying, so they end up with a patchwork rather than one consistent architecture. No plan = chaos.
That inconsistency is risky because it makes everyday operations harder: troubleshooting takes longer, and changes become unpredictable. Then there’s the technology shift. Modern growth often means bringing in analytics platforms, more tools, and more automated workflows. These are powerful, but they also add new moving parts that older setups were never designed to handle.
As we mentioned above, many companies end up in a hybrid cloud reality, where some things are on-prem, some in private cloud, some in public cloud, and they all need to work together. That adds management overhead and visibility gaps, even for experienced IT teams.
The hidden link between your tech stack and business
At the same time, infrastructure becomes more critical because the business relies on the technology stack. Technical problems become business problems almost instantly. If a server or a service goes down, it can block sales, break customer experience, stop internal operations, and create ripple effects across partners and supply chains. More systems, more integrations, more cloud configurations, more vendors, more devices mean more potential entry points for security issues.
And while all this is happening, internal IT and DevOps teams often get stretched thin. Teams struggling with staff shortages are drowning in tickets and alerts. When everything is noisy, important signals get missed, and problems can stay hidden until they explode, and that’s where alert fatigue comes in.

What happens when proper visibility is missing in IT infrastructure?
When performance issues, outages, or security gaps hit, the consequences are usually bigger than people expect. The financial side is brutal, too. In 2024, the average cost of downtime was reported at $14,056 per minute, and for large enterprises, it was $23,750 per minute.
But the cost is not just money. Outages damage trust, and that’s hard to win back. Some reporting suggests that around 60% of enterprises experience customer attrition after an outage, and reputation recovery can take months. Internally, outages create chaos. People get stuck waiting, coordination breaks down, and projects slip. It’s common to see things like employee idle time, communication breakdowns between departments (around 38%), and project delays (around 35%).
Based on survey responses, Oxford Economics calculated that downtime costs Global 2000 companies $400B annually. That’s $200M per company per year, roughly 9% of profits. Every minute of downtime costs an average of $9,000 or $540,000 per hour. And one of the most frustrating parts is that a lot of outages are not any sort of advanced hacker events or mysterious failures. They come from human error under pressure, especially when teams are understaffed, rushed, or operating without clear processes and visibility.
Server Managed Observability: WeAre OneView Center
So, how should you deal with it in practice? The goal is not to make everything perfect overnight. The goal is to reduce risk and regain control. That usually means a few basics done well, consistent standards, clear visibility across environments (so hybrid setups don’t create blind spots), smarter alerting (so teams see what matters instead of drowning in noise), and proactive monitoring that helps you catch issues early before they become downtime.
This is the exact problem space where the WeAre Observability Operations Center OneView package fits, and in the next section, we’ll go into how it changes teams’ approach from reactive to proactive.
What is WeAre OneView Center?
Observability Operations Center OneView is designed to change that dynamic by providing clear, proactive visibility into server infrastructure across on-prem, cloud, and hybrid environments. Delivered as a managed service, OneView provides a single, reliable view of server behavior over time, eliminating the need for scattered dashboards and noisy alerts.
It continuously monitors core infrastructure signals like CPU, memory, disk, network usage, and process-level behavior, and highlights early warning signs before they turn into outages. Most importantly, the visibility is centralized, so teams are not jumping between disconnected dashboards or tools to understand what is happening.
This proactive approach stands in clear contrast to traditional, reactive monitoring. In a reactive setup, problems are often first noticed by customers or end users. Teams then scramble to investigate, alerts pile up, external specialists may need to be involved, and resolution can take hours or even days. The business impact is immediate: downtime, lost productivity, frustrated customers, and reputational damage. With proactive monitoring through OneView, abnormal trends are detected early, alerts are triggered before outages occur, and issues can be resolved while they are still small. In many cases, this prevents customer impact entirely and significantly reduces the time spent on incident response.
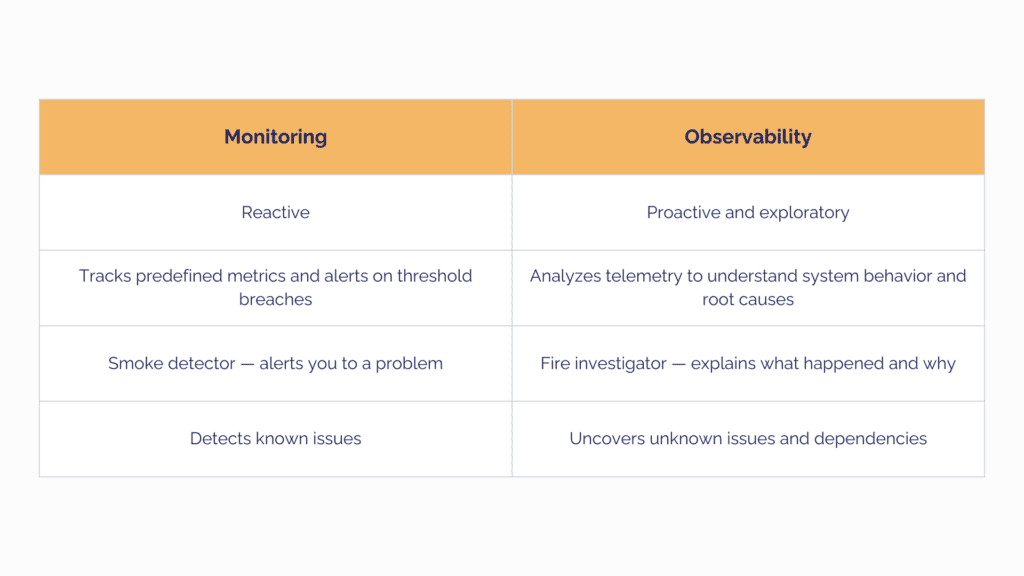
Another key difference between observability and traditional monitoring is ownership. Many organizations already have monitoring tools, but no one is clearly responsible for acting on what those tools report. OneView is not just another dashboard. It is a productized, managed service. This means alerts are clear, actions are defined, and responsibility does not fall through the cracks. Through the Observability Operations Center Service Center, monitoring is actively operated, not just passively observed. Teams do not just see problems; they know someone is accountable for addressing them.
To support different needs, OneView is offered in clear, predictable packages. For teams that want simplicity, the Essential Monitoring Package provides automated alerts, scheduled health reports, and basic support through the Observability Operations Center Service Center. For organizations that need deeper visibility and more control, the Full Insight Package adds interactive dashboards, richer reporting, and the option to upgrade to advanced service center support. The idea is to make monitoring easy to adopt, without forcing organizations into complex or oversized solutions.

Conclusion
One thing is clear: servers are the backbone of your business. With better visibility and earlier detection, organizations experience less downtime, faster incident response, and more stable business-critical systems. IT and operations teams spend less time firefighting and more time improving systems. Decision-making improves because infrastructure data is reliable and accessible, and overall operational stress is reduced. Over time, this creates a more resilient foundation for growth.
Summary
While monitoring is fundamental to identifying system issues, observability takes this further in modern environments. It provides teams with a more detailed insight into how applications behave in production, enabling them to detect issues earlier, investigate problems more quickly, and minimise their impact on users.
If you are ready to start your observability journey, you have come to the right place! Follow us on LinkedIn to enjoy weekly observability posts.
