
Optimizing Splunk Costs - How to Improve Your Splunk ROI
Splunk is a powerful tool that can help your team gain real value from data.
As organizations generate more data than ever, administrators are taking steps to maximize their Splunk ROI. We’ve seen this pattern across organizations: observability costs increase, and teams assume it’s simply the price of doing business.
But it doesn’t have to be that way. In this article, we’ll explore how to optimize Splunk license costs.
Data vs architecture - how it changes over time
The basic setup in most environments is quite straightforward. You have log sources, servers, firewalls, endpoints, applications, and they forward data into your platform. And for a long time, that works quite well.
But the environment has changed. Cloud workloads, containers, SaaS applications. The number of sources has grown significantly and the volume coming from each one has grown too.
The problem is that the architecture hasn’t changed to match. Most pipelines are still set up to forward everything without much filtering, straight into the platform. As a result, all data – regardless of its importance – lands in the same place and is billed the same way.
Let’s emphasize this – not all data is equally valuable.
A large portion consists of low-signal events that almost no one queries. However, they all arrive at the same place at the same price. When you look at where the cost actually comes from, you’ll usually find that it falls into one of three categories, which are described below.

Where the Splunk costs actually come from
To understand why costs keep rising, it’s not enough to look at the platform itself. The real issue starts much earlier – at the point where data is generated and begins its journey downstream.
In most environments, the flow looks the same: an event is created, a log line is written, an agent collects it, and it gets forwarded – sometimes through multiple layers – until it reaches the observability platform.
When you break down observability costs, they usually fall into three main areas:
- Ingestion
Most platforms charge based on data volume. The more you send, the more you pay. It’s a direct and immediate cost driver. - Storage
Keeping data searchable is expensive. Retaining large volumes of logs in a state ready for fast queries – often for 30, 60, or 90 days – quickly adds up. - Retention
Compliance requirements often mean keeping data for a year or longer. If that data stays in the primary platform the entire time, you’re paying premium rates for what is essentially archived information.
The uncomfortable reality is that a large portion of this cost is driven by data that is rarely, if ever, used. Verbose logs, repeated successful events, and low-signal entries often dominate ingestion volumes. Yet they provide little value in day-to-day operations or incident response.
Looking for out-of-the-box log management and archive?
Check out our solution →Why you shouldn’t ingest everything
A common approach is: “Let’s collect everything now and decide later what we need.”
In practice, that “later” rarely comes. Meanwhile, the data keeps accumulating. Retention policies continue running. And the Splunk bill grows month after month.
By the time you evaluate what’s useful, you’ve already paid for storing and processing large amounts of unnecessary data.
Decisions about data value are far more effective before ingestion than after.
Waste enters the system at every step - but most pipelines don’t address it because the question is never asked early enough.
Making decisions earlier in the pipeline avoids extra costs. It also forces teams to be more intentional about what they collect – aligning observability data with real operational needs instead of hypothetical future use cases.
Most data pipelines operate like an open stream:
Everything generated is collected
Everything collected is forwarded
Everything forwarded is stored
And somewhere downstream, someone is paying for all of it.
This model works at a small scale. But as environments grow, it creates a compounding effect. The more systems you add, the more logs you generate. And without control points, all of that volume ends up in your platform.
The result is predictable: costs increase, but visibility does not improve at the same rate.
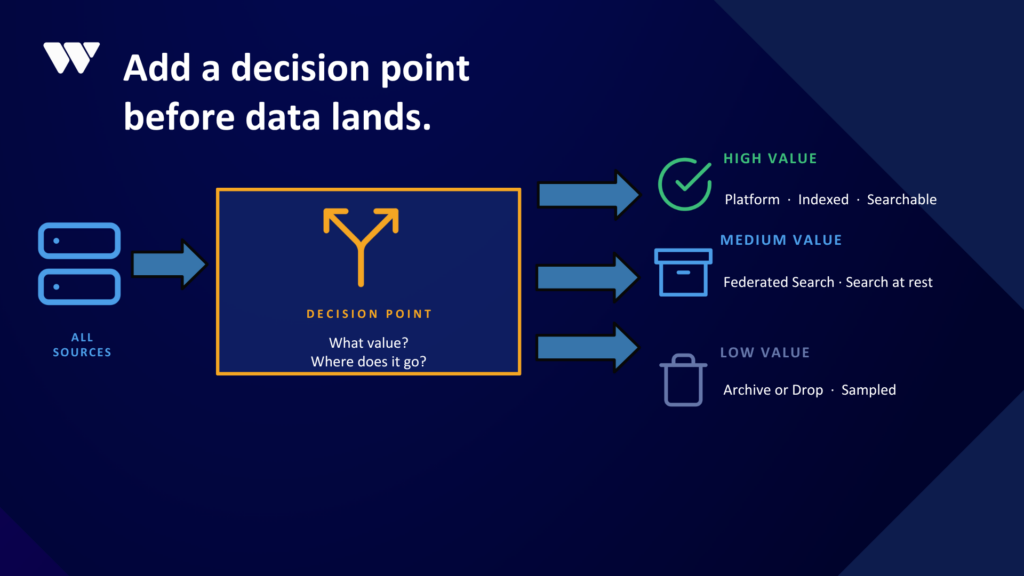
Control data upstream - three types of data
Cost optimization doesn’t require changing platforms. It requires changing how data flows into them.
A more effective model introduces filtering and routing before data reaches your observability platform:
- High-value data
Critical events such as security alerts, anomalies, and failures should go directly into your platform, fully indexed and ready for fast analysis. - Medium-value data
Data that might be useful in the future can be stored in lower-cost storage. It remains accessible but doesn’t consume expensive indexing resources. - Low-value data
Noisy, repetitive, or rarely used logs can be dropped or sampled. Keeping everything “just in case” is rarely justified when you look at actual usage patterns.
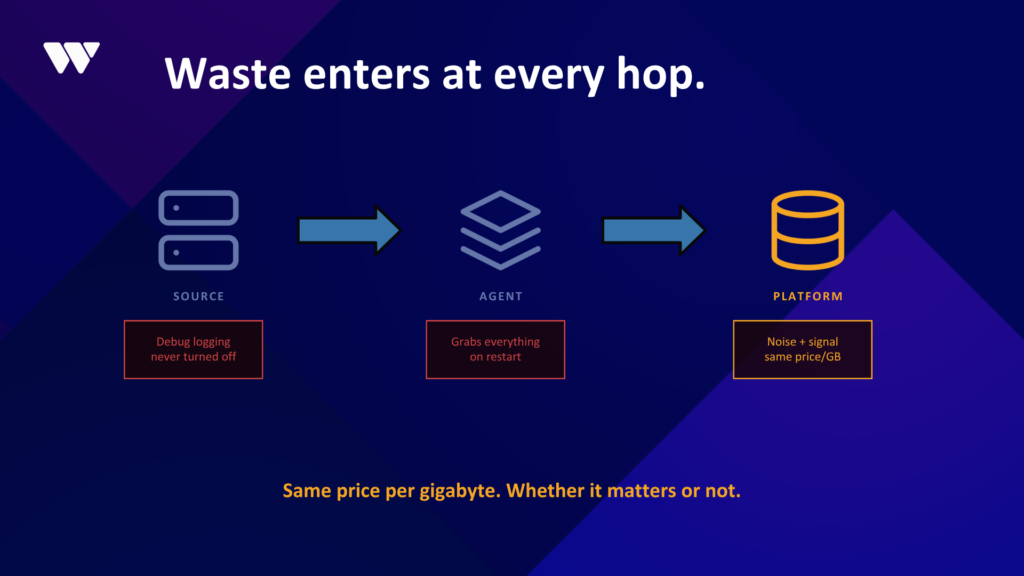
Splunk storage costs - common sources of waste
A large portion of unnecessary cost comes from very specific – and very common – sources:
Overly verbose application logging
Applications often log every operation, including routine, successful events that are never reviewed.
Debug logging left enabled
Temporary debug settings used during troubleshooting are frequently never turned off, generating high volumes of low-value data for months or even years.
Inefficient data collection at the agent level
Agents may:
- Collect entire log files on restart
- Capture fields that are never queried
- Forward duplicate or redundant data
By the time this data reaches your platform, it’s already too late – you are paying full price to store it.
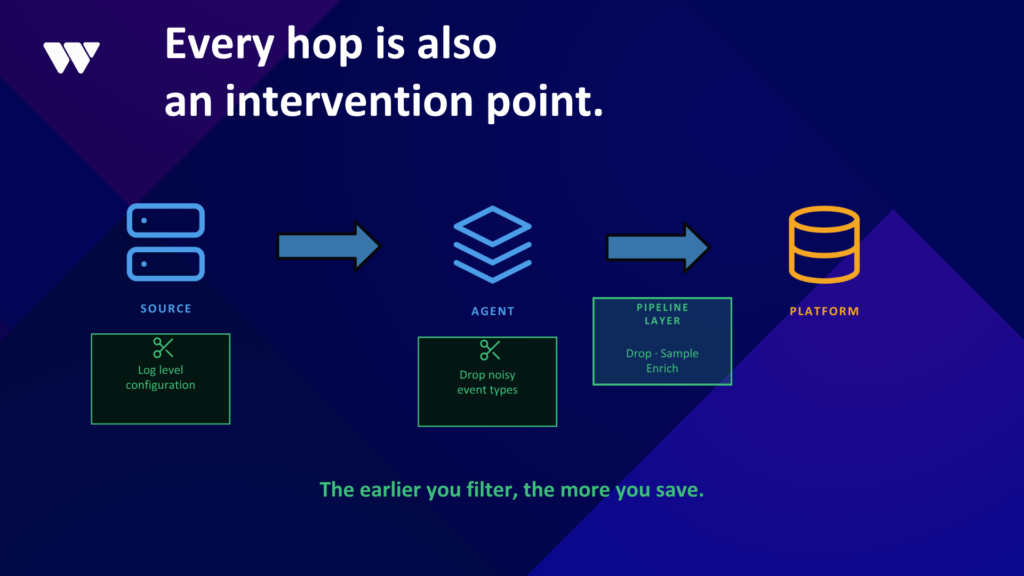
Where to reduce your Splunk data waste
The good news is that every stage in the pipeline is also an opportunity to reduce waste.
At the source
Applications should be configured to log at the appropriate level. Debug logging in production should be the exception, not the default.
At the agent
Filtering can remove clearly low-value events before they leave the host. This reduces both ingestion costs and network overhead.
Between the agent and the platform
This is where a dedicated pipeline layer can have the biggest impact:
Dropping unnecessary events
Sampling high-volume, low-value data
Enriching useful data before it arrives
Each of these steps reduces the volume of data that reaches expensive storage.
The earlier you filter, the more you save.
How do you decide which data to collect in Splunk?
If the solution is so clear, why do many organizations still ingest everything?
In most cases, it comes down to a single concern:“We might need this data someday.”
It’s a valid point. There are situations where unexpected data becomes critical during an incident or investigation. But treating all data as equally important “just in case” leads to a very expensive default.
Finding the middle ground
The choice is not binary. You don’t have to choose between indexing everything at full cost and deleting data permanently.
There is a middle ground where better architectural decisions can be made:
Keep critical data fully indexed
Store less important data in lower-cost storage
Filter or sample data that has minimal value
This approach maintains flexibility while avoiding unnecessary cost.
Final thoughts
Rising observability costs are not a mystery. They are usually the result of uncontrolled data ingestion combined with static architectures that haven’t adapted to modern environments.
The solution isn’t to abandon your platform or drastically reduce visibility. It’s to recognize that:
- Not all data has equal value
- Most environments collect far more than they use
- The most effective place to control costs is before data enters the platform
Once you shift your approach upstream, cost optimization becomes less about cutting back and more about looking at data from a business perspective.
WeAre can help you reduce your Splunk licensing costs
As an Elite Splunk Partner, we have access to more favorable licensing terms, and we can perform a comprehensive assessment of your Splunk environment.
We assess the customer’s architecture and use cases, then recommend the right capabilities for each stage. The goal is to ensure that only relevant, well-structured data is indexed and that the platform is used efficiently over the long term.
Contact us today to schedule a free consultation. Let’s talk about your Splunk journey!
Free Observability
Assessment and Consultation
30-minute expert consultation
Custom improvement roadmap
Detailed assessment report
Facebook
Twitter
LinkedIn